tl;dr

We found that 10% of the 666 most popular Python open source GitHub repositories had the following f-string typo bugs:
fprefix was missing:"hello {name}"instead off"hello {name}".fprefix was written inside the string:"fhello {name}"instead off"hello {name}". We even saw an example of"hello f{name}".- Concatenated strings used the
fprefix on only the first string:f"hello {name}" + "do you like {food}?"instead off"hello {name}" + f"do you like {food}?.
We fixed the problems we found in 69 of the most popular open source Python repositories — repositories you probably know and might even use. At the bottom of this page is a list of the GitHub pull requests we created but for the sake of summary some were Tensorflow, Celery, Ansible, DALI, Salt, Matplotlib, Numpy, Plotly, Pandas, Black, readthedocs.org, Scipy, PyTorch, rich, and some repositories from Microsoft, Robinhood, Mozilla, and AWS.
Why not follow me on Twitter to if you like this type of thing.
What is f-string interpolation?
Literal String Interpolation aka f-strings (because of the leading character preceding the string literal) were introduced by PEP 498. String interpolation is meant to be simpler with f-strings. “meant” is foreshadowing.
Prefix a string with the letter “ f ” and it’s now an f-string:
name = "jeff"
print(f"My name is {name}")
The mistakes/bugs/issues
We checked 666 most popular Python open source repositories on GitHub and found 10% of them had three types of f-string bugs, all of which broke the formatting leading to the value of the interpolated variable not being included in the string when evaluated at runtime.
Mistake 1: Missing f prefix
This was the most common case we found, and occurred mostly during logging and raising exceptions. This makes sense because logging and exception raising is a common use case for printing variable values into string messages. Take this example from pymc:
for b in batches:
if not isinstance(b, Minibatch):
raise TypeError("{b} is not a Minibatch")
Some developer debugging that TypeError is not going to have a great time as they will not immediately know what b equals due to the missing f prefix.
Mistake 2: accidentally including f inside the string
This is probably the hardest for a code reviewer to spot because if we give the code a cursory look before quickly typing “LGTM!” we can see there is an f at the start of the string. Take this example from Lean, would you spot it the f in the wrong place?
RateOfChangePercent('f{symbol}.DailyROCP({1})', 1)
Or this problem in Keras?
raise ValueError('f{method_name} `inputs` cannot be None or empty.')
Or this one from Buildbot
metrics.Timer("f{self.name}.reconfigServiceWithBuildbotConfig")
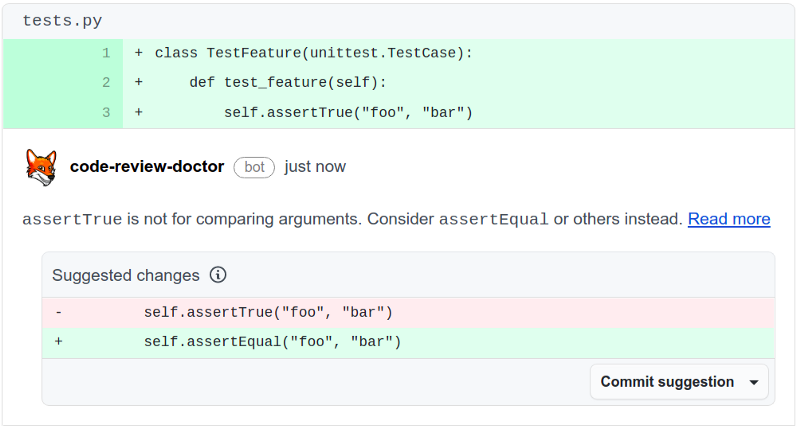
Many developers would not notice this during code review because this is a type of error humans are bad at spotting. Humans often see what they expect to see, not what is really there. That’s what makes static analysis checkers so important, especially ones that can also suggest the fix like so:

This highlights that for manual processes like code review to detect 100% of bugs 100% of the time then 100% of humans must perform 100% perfectly during code review 100% of the time. See the cognitive dissonance? We do code review because we expect human error when writing the code, but then expect no human error when reviewing the code. This dissonance results in bugs being committed.
Mistake 3: f-string concatenation
During concatenation only the first string is prefixed with f . In this example from Tensorflow the second string in the concatenation is missing the f prefix:
raise ValueError(
f"Arguments critical_section_def={critical_section_def} "
"and shared_name={shared_name} are mutually exclusive. "
"Please only specify one of them."
)
This type of f-string bug is perhaps the most interesting because a pattern emerges when we look at all of the example of this issue:
- The first string in the concatenation is correctly prefixed with
f. - The second string is not prefixed with
f.
We may be looking too deep into this but it seems like many developers think when string concatenation occurs it’s enough to declare the first string as an f-string and the other strings are turned into f-strings by osmosis. It doesn’t. We’re not suggesting this is the case for all developers that accidentally did this error, but interesting nonetheless.
The impact of f-string bugs
Based on the 666 repositories we checked, broken string interpolation due to typos most commonly occurs during logging, exception raising, and during unit testing. This therefore impacts confidence in the proper functioning of the code, and also impacts developer efficiencies when debugging.
f-string mistakes during logging
Bad string interpolation during logging means the information the code author intended to express will not actually be available to the developer trying to debug the code. For example see this code taken from Celery:
try:
self.time_to_live_seconds = int(ttl)
except ValueError as e:
logger.error('TTL must be a number; got "{ttl}"')
The developer will look in the logs and see got "{ttl}" and not see the value of ttl. It’s ironic that a developer will read the logs to debug something, only find another unrelated f-string bug that hinders them from fixing the original bug they were investigating.
Note also that Python docs suggest not using string formatting during logger calls. Instead use the logger’s build-in-mechanism to benefit lazy string interpolation for runtime optimisation.
f-string mistakes during exception raising
The impact is similar to the impact of bad f-string declaration during logging: it will reduce the effectiveness of a developer during debugging. Take for example this exception handling code from Microsoft CNTK:
raise ValueError(
'invalid permutation element: elements must be from {-len(perm), ..., len(perm)-1}'
)
Or this example from Tensorflow:
raise ValueError(
"{FLAGS.tfrecord2idx_script} does not lead to valid tfrecord2idx script."
)
Both of those should be f strings but are missing the f prefix.
The good news is crash reporting tools such as Sentry or Crashlyrics should show the variable value during the crash. Still makes debugging harder though, and not all projects use such tools.
f-string mistakes during unit testing
Tests give confidence that our code behaves how we want. However, sometimes it’s the tests themselves that don’t always behave how we want. Perhaps due to typos. In fact perhaps due to f-string typos. Take for example this test found in Home Assistant:
response = await client.get(
"/api/nest/event_media/{device.id}/invalid-event-id"
)
assert response.status == HTTPStatus.NOT_FOUND
The test expects a 404 to be returned due to “invalid-event-id” being used in the URL but actually the cause of the 404 is for another reason: because the device.id value was not interpolated into the string due to a missing the f prefix. The test is not really testing what the developer intended to test.
There is some poor developer out there maintaining the this part of the codebases that is relying on this test and using it as a quality gate to give them the confidence they have not broken the product but the test is not really working. It’s this kind of thing that can harm a night’s sleep! It ain’t what you don’t know that gets you into trouble. It’s what you know for sure that just ain’t so.
Detecting the bugs
Code Review Doctor is a static analysis tool that detects common mistakes and offers the fix. When adding new checkers we stress test them by analysing open source code, and then check the results to minimise false positives.
To test our new “this probably should be an f string” checker we generated a list of the most popular Python repositories on GitHub by using GitHub’s topic search API. We ran the following code (some code is skipped for simplicity):
class Client:
def get_popular_repositories(self, topic, count, per_page=100):
urls = []
q = f"topic:{topic}&order=desc&sort=stars"
url = f'https://api.github.com/search/repositories?q=q'
first_resp = self.session.get(
url=url,
params={"per_page": per_page}
)
for resp in self.paginate(first_resp):
resp.raise_for_status()
urls += [i['clone_url'] for i in resp.json()['items']]
if len(urls) >= count:
break
return urls[:count]
def paginate(self, response):
while True:
yield response
if 'next' not in response.links:
break
response = self.session.get(
url=response.links['next']['url'],
headers=response.request.headers
)
As you can see, GitHub uses the Link header for pagination. We then ran that code like:
client = Client()
clone_urls = client.get_popular_repositories(
topic='python', count=666
)
Here’s the gist of the list of GitHub repository clone URLs that was generated.
Once we got the list of most popular Python repositories we ran them through our distributed static analysis checkers on AWS lambda. This serverless approach allows us to simultaneously test hundreds of repositories with perhaps millions of lines of code without having to worry about scalability of our back-end infrastructure, and we do not require our developers to have beefy development machines, and our servers don’t go down or experience performance degradation during peak load.
Minimising false positives
False positives are annoying for developers, so we attempt to minimise false positives. We were able to do this by writing a “version 1” of the checker and running it against a small cohort of open source repositories and check for false positives, then iterate by fixing the false positives and each time increase the number of repositories in the cohort. Eventually we get to “version n” and were happy the false positives are at an acceptable rate. Version 1 was very simple:
GIVEN a string does not have an f prefix
WHEN the string contains {foo}
AND foo is in scope
THEN it’s probably missing an f prefix
This very naive approach allowed us to run the checkers and see what cases we did not consider. There were a lot of them! Here are some false positives we found:
- The string is later used in an str.format(…) call or str.format_map(…)
- The string is used in a logger call. Python logger uses it’s own mechanism for string interpolation: the developer can pass in arbitrary keyword arguments that the logger will later interpolate:
logger.debug("the value of {name} is {value}. a={a}.", name=name, value=value, a=a)" - The string is used in behave style test
@when('{user} accesses {url}.') - The “interpolation” is actually this common pattern for inserting a value into a template
some_string_template.replace('{name}', name).
The false positive that was most difficult to solve was the string later being using with str.format(…) or str.format_map(…) because there is no guarantee that the str.format(…) call occurs in the same scope that the string was defined in: the string may be returned by function to be later used with str.format(…). Our technology currently does not have the capability to follow variables around every scope and know how it’s used. This will be an interesting problem to solve.
With these false positives in mind, our BDD-style spec ends up like:
GIVEN a string does not have an f prefix
AND the string is not used with an str.format call
AND the string is not used with an str.format_map call
AND the string is not using logger’s interpolation mechanism
AND the string is not used in @given @when @then
And the string is not used in .replace(‘{foo}’, bar)
WHEN the string contains {foo}
AND foo is in scope
THEN it’s probably missing an f prefix
That is vast simplification: there are many other ways a string can “look” like it should be an f-string but actually is not.
Reaction from the community
It was interesting to write the f-string checker, it was interesting to detect how common the problem was (10% is a lot higher than we expected!), and it was interesting to auto-create GitHub pull requests to fix the issues we found.
It was also interesting to see the reaction from open source developers to unsolicited pull requests from what looks like a bot (really a bot found the problem and made the PR, but really a human developer at Code Review Doctor did triage the issue before the PR was raised). After creating 69 pull requests the reaction ranged from:
- Annoyance that a bot with no context on their codebase was raising pull requests. A few accepted the bugs were simple enough for a bot to fix and merged the pull request, but a few closed the pull requests and issues without fixing. Fair enough. Open source developers are busy people and are not being paid to interact with what they think it just a bot. We’re not entitled to their limited time.
- Neutral silence. They just merged the PR.
- Gratitude. “thanks” or “good bot”.
- A developer even reached out and asked us to auto-fix their use of using == to compare True False and None, so we did. Read more about that here.
For science you can see all the reactions (both positive and negative) here.
Protecting your codebase
You can add Code Review Doctor to GitHub so fixes for problems like these are suggested right inside your PR or scan your entire codebase for free online.
Here’s a list of pull requests we created: